官方文档:http://hadoop.apache.org/docs/r2.5.0/hadoop-project-dist/hadoop-common/SingleCluster.html
安装前准备
 这里的要求是要JAVA环境,以及JDK版本要求:
这里的要求是要JAVA环境,以及JDK版本要求:
SSH服务要求,通常SSH在系统安装的时候就安装好。
设置环境
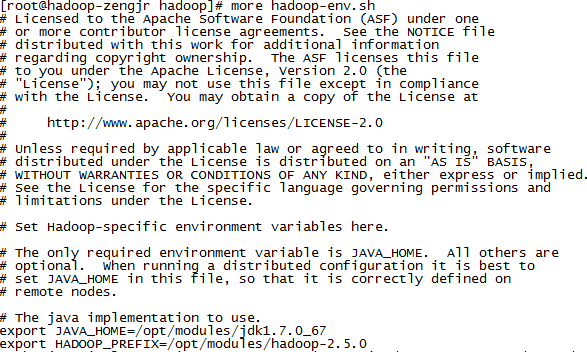
Unpack the downloaded Hadoop distribution. In the distribution, edit the file etc/hadoop/hadoop-env.sh to define some parameters as follows:
# set to the root of your Java installation
export JAVA_HOME=/usr/java/latest
# Assuming your installation directory is /usr/local/hadoop
export HADOOP_PREFIX=/usr/local/hadoop
Try the following command:
$ bin/hadoop
This will display the usage documentation for the hadoop script.
这里要求修改一下etc/hadoop/hadoop-env.sh文件,设置JAVA_HOME,HADOOP_PREFIX环境, 我这里设置如下 :
本地模式测试
命令测试
先运行一下bin下的hadoop,检查一下是否成功,设置成功后的会得到如下结果:
[zengjr@hadoop-zengjr hadoop-2.5.0]$ ./bin/hadoop
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
[zengjr@hadoop-zengjr hadoop-2.5.0]$
example程序测试
[zengjr@hadoop-zengjr hadoop-2.5.0]$ mkdir input
[zengjr@hadoop-zengjr hadoop-2.5.0]$ cp etc/hadoop/*.xml input
[zengjr@hadoop-zengjr hadoop-2.5.0]$ cd input/
[zengjr@hadoop-zengjr input]$ ls
capacity-scheduler.xml hadoop-policy.xml httpfs-site.xml
core-site.xml hdfs-site.xml yarn-site.xml
[zengjr@hadoop-zengjr hadoop-2.5.0]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar grep input output 'dfs[a-z.]+'
14/11/30 20:44:20 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
[zengjr@hadoop-zengjr hadoop-2.5.0]$ cd output/
[zengjr@hadoop-zengjr output]$ ls
part-r-00000 _SUCCESS
[zengjr@hadoop-zengjr output]$ ll
total 4
-rw-r--r-- 1 zengjr zengjr 11 Nov 30 20:44 part-r-00000
-rw-r--r-- 1 zengjr zengjr 0 Nov 30 20:44 _SUCCESS
[zengjr@hadoop-zengjr output]$ more _SUCCESS
[zengjr@hadoop-zengjr output]$ more part-r-00000
1 dfsadmin
注意一点,把上次编译的64位的native文件拷过来,覆盖解压出来的文件
cp /opt/modules/hadoop-2.5.0-src/hadoop-dist/target/hadoop-2.5.0/lib/native/* /opt/modules/hadoop-2.5.0/lib/native