spark集群安装布署
- JDK安装配置
- ssh无密码登录
- hadoop集群安装配置
- scala安装配置
- spark安装配置
前三步都都已经设置过了,现在只要进行scala和spark的安装
scala安装
安装验证如下
[zengjr@hadoop-zengjr spark]$ ls
scala-2.10.4.tgz scala-docs-2.10.4.tgz
[zengjr@hadoop-zengjr spark]$ tar zxvf scala-2.10.4.tgz -C /opt/modules/
##scala
export SCALA_HOME=/opt/modules/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
"/etc/profile" 98L, 2252C written
[root@hadoop-zengjr scala-2.10.4]# exit
exit
[zengjr@hadoop-zengjr scala-2.10.4]$ source /etc/profile
[zengjr@hadoop-zengjr scala-2.10.4]$ scala -version
Scala code runner version 2.10.4 -- Copyright 2002-2013, LAMP/EPFL
分发内容到其它机器,修改其它机器环境
scp -r scala-2.10.4/ zengjr@hadoop-slave01.xiaoqee.com:/opt/modules/
scp -r scala-2.10.4/ zengjr@hadoop-slave02.xiaoqee.com:/opt/modules/
spark安装
scp -r spark-1.2.1/ zengjr@hadoop-slave01.xiaoqee.com:/opt/modules/
scp -r spark-1.2.1/ zengjr@hadoop-slave02.xiaoqee.com:/opt/modules/
[zengjr@hadoop-zengjr modules]$ jps
5267 JournalNode
4751 QuorumPeerMain
5452 DataNode
5964 DFSZKFailoverController
8138 NodeManager
6122 NameNode
8313 Jps
spark编译
文档: http://spark.apache.org/docs/1.2.1/building-spark.html
编译
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
mvn -Phadoop-2.4 -Dhadoop.version=2.5.0 -Dprotobuf.version=2.5.0 -Pyarn -Phive -Phive-0.13.1 -Pspark-ganglia-lgpl -Phive-thriftserver -DskipTests package
成功后结果:
Finished in 1 ms
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Spark Project Parent POM .......................... SUCCESS [6:31.580s]
[INFO] Spark Project Networking .......................... SUCCESS [4:02.924s]
[INFO] Spark Project Shuffle Streaming Service ........... SUCCESS [13.186s]
[INFO] Spark Project Core ................................ SUCCESS [12:32.042s]
[INFO] Spark Project Bagel ............................... SUCCESS [58.480s]
[INFO] Spark Project GraphX .............................. SUCCESS [3:12.488s]
[INFO] Spark Project Streaming ........................... SUCCESS [3:32.578s]
[INFO] Spark Project Catalyst ............................ SUCCESS [3:45.477s]
[INFO] Spark Project SQL ................................. SUCCESS [4:15.451s]
[INFO] Spark Project ML Library .......................... SUCCESS [5:29.892s]
[INFO] Spark Project Tools ............................... SUCCESS [30.299s]
[INFO] Spark Project Hive ................................ SUCCESS [6:03.313s]
[INFO] Spark Project REPL ................................ SUCCESS [1:46.258s]
[INFO] Spark Project YARN Parent POM ..................... SUCCESS [9.942s]
[INFO] Spark Project YARN Stable API ..................... SUCCESS [1:43.722s]
[INFO] Spark Project Hive Thrift Server .................. SUCCESS [1:45.940s]
[INFO] Spark Ganglia Integration ......................... SUCCESS [18.260s]
[INFO] Spark Project Assembly ............................ SUCCESS [1:20.399s]
[INFO] Spark Project External Twitter .................... SUCCESS [45.683s]
[INFO] Spark Project External Flume Sink ................. SUCCESS [1:13.772s]
[INFO] Spark Project External Flume ...................... SUCCESS [1:00.997s]
[INFO] Spark Project External MQTT ....................... SUCCESS [13:44.861s]
[INFO] Spark Project External ZeroMQ ..................... SUCCESS [44.883s]
[INFO] Spark Project External Kafka ...................... SUCCESS [1:13.872s]
[INFO] Spark Project Examples ............................ SUCCESS [4:39.398s]
[INFO] Spark Project YARN Shuffle Service ................ SUCCESS [10.114s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 1:21:48.551s
[INFO] Finished at: Sat Feb 14 16:04:13 EST 2015
[INFO] Final Memory: 92M/583M
[INFO] ------------------------------------------------------------------------
[zengjr@hadoop-zengjr spark-1.2.1]$
可以在目录/opt/modules/spark-1.2.1/assembly/target/scala-2.10有这个包spark-assembly-1.2.1-hadoop2.5.0.jar
通过make-distribution.sh打成部署包 修改make-distribution.sh,如下:
VERSION=1.2.1
SPARK_HADOOP=2.5.0
SPARK_HIVE=1
#VERSION=$(mvn help:evaluate -Dexpression=project.version 2>/dev/null | grep -v "INFO" | tail -n 1)
#SPARK_HADOOP_VERSION=$(mvn help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | tail -n 1)
#SPARK_HIVE=$(mvn help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\
# | grep -v "INFO"\
# | fgrep --count "<id>hive</id>";\
# # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\
# # because we use "set -o pipefail"
# echo -n)
打包语句:
./make-distribution.sh --tgz -Phadoop-2.4 -Dhadoop.version=2.5.0 -Dprotobuf.version=2.5.0 -Pyarn -Phive -Phive-0.13.1 -Pspark-ganglia-lgpl -Phive-thriftserver -DskipTests package
##结果如下:
Finished in 1 ms
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Spark Project Parent POM .......................... SUCCESS [18.583s]
[INFO] Spark Project Networking .......................... SUCCESS [24.560s]
[INFO] Spark Project Shuffle Streaming Service ........... SUCCESS [15.287s]
[INFO] Spark Project Core ................................ SUCCESS [8:52.458s]
[INFO] Spark Project Bagel ............................... SUCCESS [58.349s]
[INFO] Spark Project GraphX .............................. SUCCESS [2:34.262s]
[INFO] Spark Project Streaming ........................... SUCCESS [3:57.053s]
[INFO] Spark Project Catalyst ............................ SUCCESS [3:52.841s]
[INFO] Spark Project SQL ................................. SUCCESS [4:07.589s]
[INFO] Spark Project ML Library .......................... SUCCESS [4:43.135s]
[INFO] Spark Project Tools ............................... SUCCESS [29.357s]
[INFO] Spark Project Hive ................................ SUCCESS [4:39.562s]
[INFO] Spark Project REPL ................................ SUCCESS [1:36.797s]
[INFO] Spark Project YARN Parent POM ..................... SUCCESS [6.771s]
[INFO] Spark Project YARN Stable API ..................... SUCCESS [1:42.630s]
[INFO] Spark Project Hive Thrift Server .................. SUCCESS [59.735s]
[INFO] Spark Ganglia Integration ......................... SUCCESS [11.546s]
[INFO] Spark Project Assembly ............................ SUCCESS [2:23.891s]
[INFO] Spark Project External Twitter .................... SUCCESS [54.180s]
[INFO] Spark Project External Flume Sink ................. SUCCESS [47.781s]
[INFO] Spark Project External Flume ...................... SUCCESS [1:08.434s]
[INFO] Spark Project External MQTT ....................... SUCCESS [55.674s]
[INFO] Spark Project External ZeroMQ ..................... SUCCESS [55.100s]
[INFO] Spark Project External Kafka ...................... SUCCESS [1:04.037s]
[INFO] Spark Project Examples ............................ SUCCESS [3:12.068s]
[INFO] Spark Project YARN Shuffle Service ................ SUCCESS [10.701s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 51:24.572s
[INFO] Finished at: Sat Feb 14 19:11:11 EST 2015
[INFO] Final Memory: 78M/510M
[INFO] ------------------------------------------------------------------------
[zengjr@hadoop-zengjr spark-1.2.1]$ ls
assembly CONTRIBUTING.md dist examples lib_managed network python sbt sql tox.ini
bagel core docker external LICENSE NOTICE README.md scalastyle-config.xml streaming yarn
bin data docs extras make-distribution.sh pom.xml repl scalastyle-output.xml target
conf dev ec2 graphx mllib project sbin spark-1.2.1-bin-.tgz tools
生成spark-1.2.1-bin-.tgz文件
解压部署包
[zengjr@hadoop-zengjr spark-1.2.1]$ tar -zxvf spark-1.2.1-bin-.tgz -C /opt/modules/
[zengjr@hadoop-zengjr modules]$ rm -rf spark-1.2.1
[zengjr@hadoop-zengjr modules]$ mv spark-1.2.1-bin-/ spark-1.2.1
[zengjr@hadoop-zengjr modules]$ ls
apache-maven-3.0.5 findbugs-1.3.9 hadoop-2.5.0 hadoop-2.5.0-src jdk1.7.0_67 protobuf-2.5.0 scala-2.10.4 spark-1.2.1 spark-1.2.1_bak zookeeper
[zengjr@hadoop-zengjr modules]$ cd spark-1.2.1
[zengjr@hadoop-zengjr spark-1.2.1]$ ls
bin conf data ec2 examples lib LICENSE NOTICE python README.md RELEASE sbin
[zengjr@hadoop-zengjr spark-1.2.1]$ cd conf/
[zengjr@hadoop-zengjr conf]$ ls
fairscheduler.xml.template log4j.properties.template metrics.properties.template slaves.template spark-defaults.conf.template spark-env.sh.template
##修改配置文件名称
[zengjr@hadoop-zengjr conf]$ mv spark-env.sh.template spark-env.sh
[zengjr@hadoop-zengjr conf]$ mv spark-defaults.conf.template spark-defaults.conf
可以看到spark-env.sh文件中详细的注释,locally,cluster,YARN,standalone各种运行模式,如下:
# Options read when launching programs locally with
...
# Options read by executors and drivers running inside the cluster
...
# Options read in YARN client mode
...
# Options for the daemons used in the standalone deploy mode
...
# Generic options for the daemons used in the standalone deploy mode
测试loca模式,修改spark-env.sh:
####################
HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0/etc/hadoop
JAVA_HOME=/opt/modules/jdk1.7.0_67
SPARK_LOCAL_IP=localhost
####################
测试:
[zengjr@hadoop-zengjr spark-1.2.1]$ bin/spark-shell --master local
scala> sc.textFile("file:////opt/modules/spark-1.2.1/README.md").filter(_.contains("Spark")).count
15/02/14 23:07:24 INFO storage.MemoryStore: ensureFreeSpace(170332) called with curMem=0, maxMem=280248975
15/02/14 23:07:24 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 166.3 KB, free 267.1 MB)
15/02/14 23:07:24 INFO storage.MemoryStore: ensureFreeSpace(23947) called with curMem=170332, maxMem=280248975
15/02/14 23:07:24 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 23.4 KB, free 267.1 MB)
15/02/14 23:07:24 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:57886 (size: 23.4 KB, free: 267.2 MB)
15/02/14 23:07:24 INFO storage.BlockManagerMaster: Updated info of block broadcast_0_piece0
15/02/14 23:07:24 INFO spark.SparkContext: Created broadcast 0 from textFile at <console>:13
15/02/14 23:07:25 INFO mapred.FileInputFormat: Total input paths to process : 1
15/02/14 23:07:25 INFO spark.SparkContext: Starting job: count at <console>:13
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Got job 0 (count at <console>:13) with 1 output partitions (allowLocal=false)
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Final stage: Stage 0(count at <console>:13)
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Parents of final stage: List()
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Missing parents: List()
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Submitting Stage 0 (FilteredRDD[2] at filter at <console>:13), which has no missing parents
15/02/14 23:07:25 INFO storage.MemoryStore: ensureFreeSpace(2752) called with curMem=194279, maxMem=280248975
15/02/14 23:07:25 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 2.7 KB, free 267.1 MB)
15/02/14 23:07:25 INFO storage.MemoryStore: ensureFreeSpace(1978) called with curMem=197031, maxMem=280248975
15/02/14 23:07:25 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 1978.0 B, free 267.1 MB)
15/02/14 23:07:25 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:57886 (size: 1978.0 B, free: 267.2 MB)
15/02/14 23:07:25 INFO storage.BlockManagerMaster: Updated info of block broadcast_1_piece0
15/02/14 23:07:25 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:838
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from Stage 0 (FilteredRDD[2] at filter at <console>:13)
15/02/14 23:07:25 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
15/02/14 23:07:25 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 1303 bytes)
15/02/14 23:07:25 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
15/02/14 23:07:25 INFO rdd.HadoopRDD: Input split: file:/opt/modules/spark-1.2.1/README.md:0+3629
15/02/14 23:07:25 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
15/02/14 23:07:25 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
15/02/14 23:07:25 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
15/02/14 23:07:25 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
15/02/14 23:07:25 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
15/02/14 23:07:25 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 1757 bytes result sent to driver
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Stage 0 (count at <console>:13) finished in 0.161 s
15/02/14 23:07:25 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 131 ms on localhost (1/1)
15/02/14 23:07:25 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/02/14 23:07:25 INFO scheduler.DAGScheduler: Job 0 finished: count at <console>:13, took 0.417815 s
res0: Long = 19
测试standalone模式,修改spark-env.sh:http://spark.apache.org/docs/latest/spark-standalone.html
####################public
HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0/etc/hadoop
JAVA_HOME=/opt/modules/jdk1.7.0_67
##############local
#SPARK_LOCAL_IP=localhost
####################standalone
SPARK_MASTER_IP=localhost
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1G
SPARK_WORKER_INSTANCES=1
####################
修改spark-default.conf
spark.master spark://localhost:7077
启动master:
./sbin/start-master.sh
启动worker:
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
或者
sbin/start-all.sh
验证:
http://hadoop-zengjr.xiaoqee.com:8080/
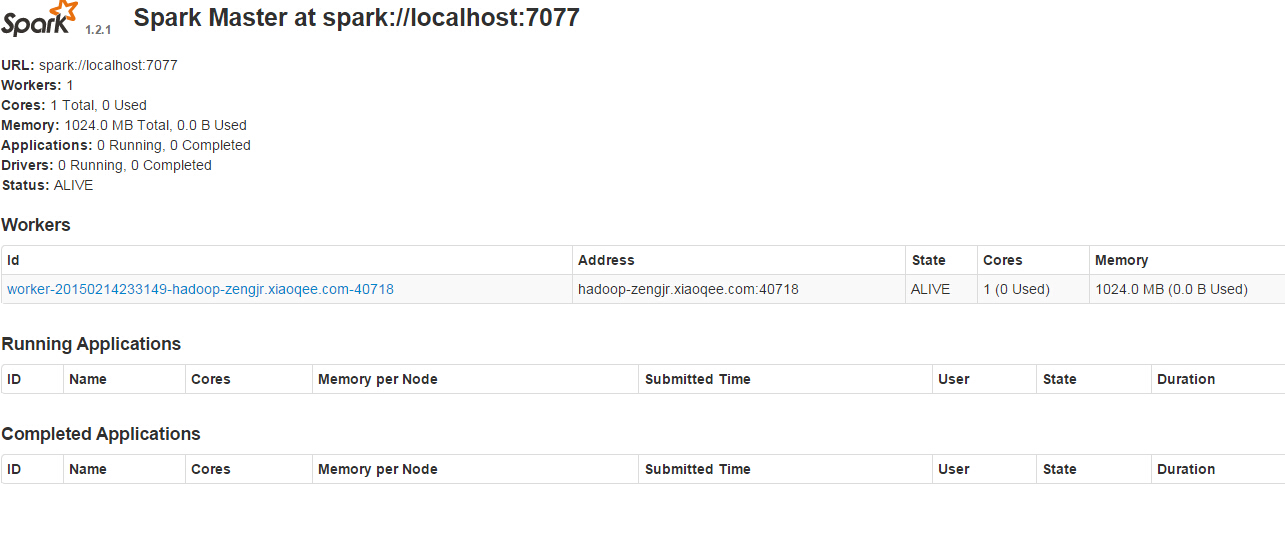
#spark-shell测试
./bin/spark-shell --master spark://localhost:7077
#测试:
sc.textFile("file:////opt/modules/spark-1.2.1/README.md").filter(_.contains("Spark")).count
测试yarn模式,关闭standalone,修改spark-env.sh
####################public
HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0/etc/hadoop
JAVA_HOME=/opt/modules/jdk1.7.0_67
##############local
#SPARK_LOCAL_IP=localhost
####################standalone
#SPARK_MASTER_IP=localhost
#SPARK_MASTER_PORT=7077
#SPARK_WORKER_CORES=1
#SPARK_WORKER_MEMORY=1G
#SPARK_WORKER_INSTANCES=1
####################YARN
SPARK_EXECUTOR_INSTANCES=1
SPARK_EXECUTOR_CORES=1
SPARK_EXECUTOR_MEMORY=1G
SPARK_DRIVER_MEMORY=512M
####################
修改spark-default.conf
spark.master yarn-client
启动:
bin/spark-shell
#测试:
sc.textFile("file:////opt/modules/spark-1.2.1/README.md").filter(_.contains("Spark")).count
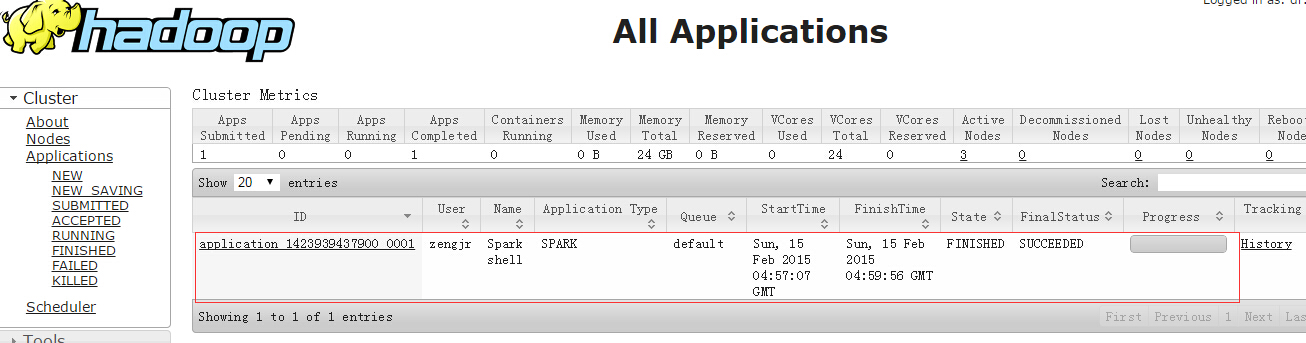
在网页上http://hadoop-slave01.xiaoqee.com:8088/cluster